
Symphony of Voice: The Evolution of AI’s Orchestration Layer in Voice Technology

Imagine speaking to a computer as effortlessly as to a friend – your words, tone, and emotion all understood in concert.
Voice AI has come a long way from simple “talking machines” to today’s intelligent assistants. At the heart of this revolution is the orchestration layer – the conductor coordinating speech recognition, language understanding, and speech synthesis into a harmonious interaction. This epic explainer will trace the origins of the orchestration layer from early voice interfaces, examine the classic speech-to-text → AI → text-to-speech pipeline (and key technologies like Whisper, Deepgram, and OpenAI’s models), explore how it’s evolving to overcome limitations (like loss of emotional nuance), and envision a future where voice AI feels truly human. Throughout, we’ll combine storytelling with deep technical insight, showing how this technology’s journey can inspire innovators here in Hastings, Minnesota and beyond.
Origins: Early Voice Interfaces and the Birth of Orchestration
Long before Siri or Alexa became household names, researchers dreamed of machines that could hear and speak. The mid-20th century saw pioneering (if primitive) voice systems that laid the groundwork. In 1952, Bell Labs built “Audrey,” a device that could recognize spoken digits 0–9 for telephone dialing medium.com. A decade later, IBM introduced the Shoebox (1961), often cited as the first digital speech recognizer, capable of understanding 16 spoken words and 9 digits voicebot.ai. These early contraptions were marvels of their time – Shoebox was even demoed at the 1962 World’s Fair – but they were extremely limited. Notably, while they converted speech to electrical or text signals, they could not talk back. As one retrospective points out, Audrey and Shoebox “were equipped with speech-to-text technology [but] lacked a backwards text-to-speech method,” meaning they couldn’t respond with voice medium.com. The interaction was one-way, so there was no need yet for an orchestration layer – there simply wasn’t a complex dialogue to manage.
As computing power grew, so did ambition. By 1972, Carnegie Mellon’s Harpy system could recognize about 1,000 words, a huge leap in vocabulary size for voice recognition. In the 1980s and 90s, commercial speech recognition arrived (e.g. Dragon Dictate in 1990, albeit costing $6,000) voicebot.ai. Systems were still mostly command-and-control: you’d say a phrase, the computer would execute a function or transcribe text. Behind the scenes, though, the idea of modularity was emerging. Engineers found it useful to separate the voice pipeline into components – one for converting audio to text, another for processing the text (understanding intent or retrieving info), and another for producing a response. Early voice applications in call centers and car navigation, for instance, began to have a proto-orchestration: a simple flow connecting Automatic Speech Recognition (ASR) to a dialogue manager and then to Text-to-Speech (TTS).
The true dawn of the orchestration layer came in the 2000s and early 2010s with the rise of virtual assistants. Apple’s Siri, launched in 2011, was the first voice assistant to reach a wide audience voicebot.ai. What made Siri and its successors (Google Now, Cortana, Amazon Alexa, etc.) special was not just better recognition, but integration of multiple AI services. Say you asked Siri, “Book a table at an Italian restaurant near me.” Siri would transcribe your speech via cloud-based ASR (originally powered by Nuance), then interpret the request (natural language understanding to figure out you want a restaurant reservation), then orchestrate a set of services – Yelp for restaurant info, Maps for location, OpenTable for booking – and finally compose a response and speak it back to you. Tom Gruber, one of Siri’s creators, described this as “service orchestration”: Siri could take a user request and delegate parts of it to different services, then combine the results into a useful answer tomgruber.org. In other words, Siri introduced a layer that sits between voice input and voice output, managing a whole symphony of tasks in between. This was the orchestration layer in action (even if Apple didn’t call it that publicly at the time). By 2014, Amazon’s Alexa further popularized this architecture – you speak to Alexa, and behind the scenes an orchestrator routes your request to the appropriate “skill” or API, then gathers the response and speaks it. The orchestration layer had become the connective tissue of voice interfaces, coordinating speech recognition, language processing, and action-taking.
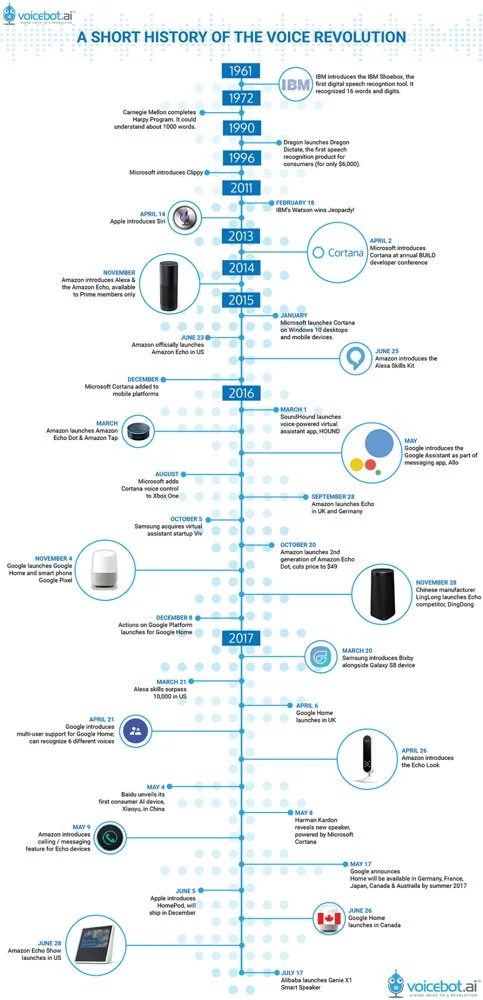
Timeline of major milestones in voice assistant technology, “A Short History of the Voice Revolution.” Early systems in the 1950s–60s could only listen (one-way). By the 2010s, smartphones and smart speakers brought two-way voice assistants (Siri, Alexa) to the mainstream, powered by cloud-based speech recognition and ever-improving AI. The rapid expansion after 2011 shows how voice AI exploded once the orchestration of accurate ASR, intelligent dialogue, and natural TTS became feasible.
Crucially, as these assistants got more capable, the orchestration layer grew more sophisticated. It not only passed along data but made decisions: for example, Alexa’s system would decide which skill should handle a user’s request (“Is this a music request, a weather query, or a joke?”). Or consider multi-turn dialogue: if the AI needed clarification, the orchestrator had to loop back and ask the user a follow-up question. By the late 2010s, the voice AI architecture had solidified into a pipeline with an orchestration layer at its core, enabling complex conversational experiences. But how exactly does this pipeline work? Let’s dive into the traditional model.
The Traditional Voice AI Orchestration Layer: Speech→LLM→Speech
By now, the standard approach to voice AI can be seen as a three-act process, orchestrated to feel seamless to the user. In Act I, the system listens (captures and transcribes your speech). Act II, it thinks (processes the transcript with an AI language model or other logic to decide on a response). Act III, it speaks (synthesizes a voice reply). The orchestration layer is the invisible stage manager ensuring these acts happen in order, correctly and fast. Modern implementations often break this into three modular components: Speech-to-Text (STT), an LLM or dialogue manager, and Text-to-Speech (TTS) dev.to. Let’s unpack each:
Speech-to-Text (Transcription) – This is the “ears” of the system. Audio waveform input from a microphone is converted to text. Thanks to deep learning, STT accuracy has skyrocketed in recent years. For example, OpenAI’s Whisper model (2022) can transcribe speech with human-level accuracy across many languages, even in real-time. Other state-of-the-art engines like Deepgram (a popular enterprise STT API) and Google’s Cloud Speech API can handle even noisy or accented speech. The transcriber might run on-device or in the cloud, and can even stream partial results (so the system doesn’t have to wait for you to finish speaking to start processing) docs.vapi.ai. By the end of this stage, the user’s spoken words are captured as plain text.
Language Model / Brain – This is the “mind” of the voice assistant, typically taking the transcribed text and figuring out what to do or say. In older systems, this role was filled by rule-based scripts or intent classifiers plus a bunch of if-then logic. Today, increasingly, it’s a Large Language Model (LLM) – essentially a powerful AI trained on vast amounts of text that can understand context and generate answers. OpenAI’s GPT series (e.g. GPT-4) is a prime example, as are others like Google’s LaMDA or Meta’s LLaMA. The text transcript is fed into the LLM (often as part of a “prompt” possibly with some predefined instructions), and the LLM outputs a response in natural language docs.vapi.ai. This could be an answer to a question, an action confirmation (“Sure, booking a table at 7pm...”), or any appropriate reply. The LLM is effectively doing what we used to call natural language understanding and generation all in one. It’s the reasoning engine. (Notably, some architectures might involve additional reasoning or tools here – for example, an orchestration layer might route the text to a database query or a calculation module if needed, but even that decision can be made by an LLM or a simple policy.)
Text-to-Speech (Synthesis) – This is the “voice” of the system – turning the AI’s reply text into audible speech. Early TTS systems were robotic, but today’s are often so natural that it’s hard to tell AI from a human speaker. Companies like ElevenLabs and Google (WaveNet, etc.) have models that capture human-like prosody and even emotion in generated speech. The text output from the LLM is sent to a TTS engine, which produces an audio waveform that says that text out loud docs.vapi.ai. This could be done via cloud services (Amazon Polly, Microsoft Azure TTS, etc.) or on-device if lightweight enough. The result: the assistant talks back to you.
Behind the curtain, the orchestration layer links these components. A platform like VAPI.ai describes itself as “an orchestration layer over three modules: the transcriber, the model, and the voice” docs.vapi.ai. It doesn’t matter which specific AI providers are used – you could plug in OpenAI Whisper or Deepgram for transcription, GPT-4 or an open-source LLM for the brain, ElevenLabs or Google TTS for the voice – the orchestration layer makes sure the data flows and the conversation feels natural. It handles things like passing the live audio stream to the STT service, feeding the transcript into the LLM prompt, streaming the LLM’s text output into the TTS (for low latency), and maybe even managing barge-in (if the user interrupts the AI, it needs to stop talking). As VAPI’s docs note, the orchestration layer also optimizes latency and streaming, and “orchestrates the conversation flow to make it sound human” docs.vapi.ai. In essence, it’s the glue and timing manager.
To visualize the traditional pipeline, consider the following diagram of the data flow in a voice AI app:

A typical voice AI pipeline orchestrated in five steps. (1) The user’s speech is captured as an audio waveform. (2) A Speech-to-Text module transcribes the audio to text. (3) The text is sent into the program logic/LLM (the “brain”), which produces a text reply. (4) A Text-to-Speech module converts the reply text into speech audio. (5) The spoken response is played back to the user. The orchestration layer coordinates this entire flow, ensuring each part delivers its output to the next and managing the interaction state. dev.to, dev.to
In concrete terms, imagine you ask “What’s the weather today?”. Your phone’s microphone records your voice (step 1), the STT engine transcribes it to “what’s the weather today?” (step 2), the text is fed to the LLM which interprets it and maybe queries a weather API (step 3), the LLM responds with “The forecast is 75°F and sunny.”, that sentence is sent to TTS (step 4) which generates the audio of a pleasant voice saying “The forecast is 75°F and sunny.”, and finally you hear the answer (step 5). All of this can happen within a second or two, thanks to efficient orchestration. The user perceives it as one smooth conversation with the AI.
Let’s summarize the components and some example technologies:
Component
Role in Orchestration Layer
Modern Examples
Speech-to-Text (STT)
Transcribe spoken audio into text (the assistant’s “ears”).
OpenAI Whisper, Deepgram, Google Speech API, Microsoft Azure Speech.
Language Model / NLU
Understand the text and decide on a response (the “brain”). Often a large language model or dialogue manager.
OpenAI GPT-4 (and other GPT models), Anthropic Claude, Google LaMDA, IBM Watson Assistant.
Text-to-Speech (TTS)
Synthesize voice audio from text (the assistant’s “voice”).
ElevenLabs Prime Voice, Google WaveNet (Cloud TTS), Amazon Polly, Microsoft Neural TTS.
How the orchestration layer works: In a traditional setup, the orchestration layer is essentially a controller that sequences these components: it takes the text from STT and feeds it into the LLM, takes the LLM’s output and feeds it to TTS. In many implementations, it’s also handling context – for example, keeping track of conversation history to send as part of the LLM prompt (so the AI remembers what was said earlier), or handling error cases (if the STT returns “[inaudible]”, the orchestrator might ask “Can you repeat that?”). In a sense, it’s like a pipeline manager or an API orchestrator. Cloud services like Amazon Lex, Google Dialogflow, or Microsoft’s Bot Framework can be seen as offering this orchestration logic (with some built-in speech and language AI). But developers often craft their own orchestration logic using APIs from specialized providers.
One key point is that each component can be swapped or improved independently – and indeed they have improved drastically. OpenAI’s Whisper (an ASR model) set new benchmarks for transcription quality github.com. OpenAI’s GPT-3 and GPT-4 showed astonishing leaps in language understanding and generation. New TTS models like VALL-E and ElevenLabs produce expressive, human-like voice outputs. The orchestration layer makes these innovations work together: e.g. you can pair Whisper + GPT-4 + ElevenLabs to build a very lifelike voice assistant, where Whisper ensures it hears you accurately, GPT-4 ensures it understands and answers intelligently, and ElevenLabs ensures it speaks with a natural voice. Platforms like the one from Daily.co illustrate how developers combine these: “You need three basic components to get started building an LLM application: STT, the LLM, and TTS… Interestingly, all of these are AI” and can be run via cloud services dev.to. The orchestration binds them into a single user experience.
The Human Touch – Today’s Orchestration Achievements
Before moving on, it’s worth appreciating how far the traditional pipeline has brought us. With the orchestration layer in place, voice AI went from rigid and robotic to (sometimes) surprisingly human-esque. We can have open-ended conversations with our devices, ask follow-up questions, even get jokes or stories. In an optimal setup, the user doesn’t sense the underlying pipeline; it feels like talking to an intelligent entity. Modern systems also optimize for real-time performance – sometimes doing steps in parallel. For instance, Google Assistant can start responding (via TTS) before you’ve finished speaking or before it’s 100% done thinking – it might use partial STT results to anticipate a reply. This streaming orchestration is tricky but adds to the illusion of a fluid conversation.
However, despite these advances, the traditional model has some limitations that become apparent as we push voice AI to be more emotionally aware and engaging. In the next section, we’ll explore those limitations and how researchers are addressing them.
Evolution and Limitations: From Perfecting Speech to Understanding Emotion
The classic STT→LLM→TTS pipeline has dramatically improved over the past decade in terms of accuracy and fluency. Yet, users and designers noticed something was missing: the nuance and emotion of human conversation. Even as voice assistants spoke with more natural tones and parsed words correctly, they often failed to grasp or convey the subtext – the feeling behind the words. This is a key limitation of an orchestration layer that treats speech merely as text to be converted and generated.
Loss of Emotional Nuance: One of the biggest challenges is that when speech is converted to text, a lot of information is lost. Human speech carries rich emotional and contextual cues – tone of voice, pitch, volume, hesitation, laughter, stress on certain words, etc. When an ASR system produces a transcript, none of that appears in the text. As a recent research review noted, “the ubiquity of STT applications… has significantly contributed to breaking communication barriers… However, the inherent challenge lies in the loss of emotional nuance during the transcription process” arxiv.org. Essentially, the orchestration layer’s first step strips away the speaker’s emotion. If you say “I’m fine!” in an angry, terse tone, the text “I’m fine!” might mislead the AI to think you’re actually fine, when you’re not. Likewise, sarcasm, excitement, sadness – a pure text representation won’t capture these reliably.
This limitation leads to interactions that can feel flat or inappropriate. A user might be frustrated or crying, and a voice assistant, oblivious to those signals, responds in a cheery monotone or gives a tone-deaf answer. To humans, this mismatch is glaring – we expect an interlocutor to react to our tone (think of a friend asking “Are you okay? You sound upset.”). Traditional voice AIs don’t do that because their orchestration pipeline doesn’t carry emotion forward – it was never part of the “language” the AI brain understood.
Early efforts to address nuance: Developers realized this issue and started bolting on solutions. One approach was sentiment analysis or emotion detection on the input audio or text. For example, some contact center AI systems now include an extra step after transcription that analyzes the audio’s waveform for emotional tone or the text for sentiment. The blog of one voice AI system describes using a speech-to-speech engine that does phoneme-level and sentiment analysis to detect emotional cues and conversational nuance from the audio assembled.com. These systems attempt to figure out if the customer sounds angry, confused, or happy, and then feed that info into the decision-making. In our orchestration terms, that means the orchestration layer might attach an “emotion tag” to the text (like <angry> or a numeric sentiment score) and give that to the language model.
Another clever workaround was proposed in a research paper by Hu et al., which developed an “emojilization” tool: essentially, after getting the transcribed text, automatically attach emojis to it to represent the inferred emotion arxiv.org. For example, the sentence “I’m fine” might become “I’m fine 😠” in the presence of angry vocal cues. Their pilot study found that readers could better grasp the speaker’s emotion with these emojis than with plain text arxiv.org. While a bit hacky, it’s an attempt to reintroduce lost information back into the text before the AI processes it.
On the output side, there have been improvements in making synthesized speech more expressive. Many TTS systems allow some control over style or tone. For instance, Alexa’s TTS can be instructed via SSML to speak joyfully or sadly. These are manual controls – essentially the orchestration layer choosing a specific voice style for the response. But the assistant itself still typically doesn’t decide on the emotional tone; it’s usually pre-set by developers in certain contexts (“use a cheerful tone when greeting the user in the morning,” etc.).
Despite these patches, a fundamental issue remained: the traditional pipeline doesn’t deeply integrate emotion or non-verbal signals into the AI’s understanding. The LLM or dialogue manager, if it only gets plain text, can’t read between the lines as humans do. It might catch explicit sentiment words (“I am furious”), but it won’t know the user sounded furious unless we change how we feed it data.
Other limitations: Beyond emotional nuance, there are a few related limitations in the traditional orchestration approach:
Context and Memory: While advanced LLMs can maintain context through text, earlier systems would often lose track of context between turns unless explicitly handled. The orchestration layer would have to manage a memory of past dialogue states. Newer models have improved this by taking the full conversation history as part of the prompt, but very long conversations can still exceed input limits, requiring the orchestrator to summarize or truncate history.
Latency vs. Accuracy: The pipeline nature can introduce delay – each step adds some processing time. Developers must carefully optimize (e.g., streaming audio, partial transcripts, parallelizing the next step) to make conversation real-time. The orchestration layer may decide when to start TTS (perhaps before the LLM text is fully ready, to save time). This is an engineering constraint: speed is generally good now (with modern models and hardware), but if using a huge LLM or a slow network, lag can occur and break the illusion of a natural exchange. Orchestration has evolved to support streaming mode to mitigate this.
Error propagation: If the ASR makes a mistake in transcription, the AI’s reply could be off-mark because it’s “hearing” the wrong thing. For instance, “play The Sound of Music soundtrack” misheard as “play the sound of mew sick” might confuse the LLM. Traditional orchestrators don’t inherently fix ASR errors, though some systems might do confidence scoring and reprompt the user or have a correction step. Newer end-to-end approaches aim to reduce these errors by jointly optimizing components.
The evolution of the orchestration layer thus has been about adding more intelligence and awareness to the pipeline to tackle these issues. This is where cutting-edge research is pointing the way to a new paradigm: making the orchestration itself multimodal and contextual, rather than just shuttling plain text. Let’s look at how new approaches are transforming the orchestration layer to address especially the emotional nuance problem.
New Approaches: Multimodal Tokens and Emotionally Intelligent Orchestration
To overcome the limitations above, researchers and companies are rethinking how a voice AI’s components interact. The buzzword leading the charge is multimodality – enabling AI models to handle multiple modes of data (text, audio, images, etc.) simultaneously. Instead of treating speech as “just text after transcription,” the next generation orchestration layer aims to feed the AI richer inputs that include acoustic information, and to generate outputs that carry emotional and auditory qualities seamlessly. A key concept here is using multimodal tokens or intermediate representations that preserve more than just words.
What are multimodal tokens? In simple terms, it means encoding various data (like audio or visuals) into a unified format (a sequence of tokens) that a language-model-style AI can process. Think of tokens as the common language inside the AI’s brain. Traditional LLMs take text tokens (words, subwords) as input. But imagine we also had tokens representing audio features – for example, a sequence of vectors or symbols encoding not only what was said but how it was said. Recent research indeed is moving in this direction. A paper in 2023 introduced AnyGPT, an “any-to-any” multimodal model that can handle speech, text, images, music, etc., by converting each modality into sequences of discrete symbols that the model can ingest medium.com. Unlike continuous raw audio waveforms, these discrete audio tokens are more abstract and easier for a transformer model to work with. AnyGPT showed that using this approach, one can have a single AI model take in, say, spoken audio and output an image or take in text and output speech – because internally it’s all just tokens and the model has been trained to learn the mappings medium.com. The advantage here is unification: the boundaries between STT, LLM, and TTS begin to blur. They become one model or closely linked models speaking a shared token language.
In the context of voice orchestration, using multimodal tokens means that instead of dropping all the prosody when transcribing, the system could produce a richer representation. For instance, OpenAI’s Whisper model has an option to output tokens for things like <|laugh|> or <|silence|> for pauses. But we can go further – research projects like Google’s AudioLM and related works convert audio into semantic tokens (capturing the content of speech at a high level) and acoustic tokens (capturing the actual sound details like voice timbre). An open-source project called WhisperSpeech built a text-to-speech system by inverting Whisper – it uses Whisper to generate semantic tokens from input speech, then uses those tokens (instead of raw text) to drive speech synthesis github.com. This indicates that Whisper’s internal representation retains a lot of the speech characteristics. The WhisperSpeech team even notes plans to condition generation on emotions and prosody github.com, meaning they want to allow control of the emotional tone in the output by leveraging those richer tokens.
Emotion-aware AI reasoning: Another promising approach is to explicitly train models that incorporate emotion recognition into the language understanding phase. A recent paper (2025) introduced a framework called JELLY that “enables the LLM to perceive emotions in speech” by integrating a specialized encoder with Whisper to detect the speaker’s emotion, and then fine-tunes the LLM to use that emotional context when generating its response arxiv.org. Essentially, JELLY gives the LLM two inputs: the textual content and an embedding of the emotion behind it. The results showed the system produced replies with more appropriate emotional tone in a conversation, and the synthesized speech aligned better with the context arxiv.org, arxiv.org. This is a big step: it means the orchestration layer is no longer passing forward just text, but also an emotional vector or tag, and the AI “brain” is modified to take that into account in deciding what to say and how to say it.
To illustrate with a scenario: You say to a future AI assistant, “Yeah, I love waiting on hold for an hour.” The audio carries a clear sarcastic tone. A traditional system might get the text and think you genuinely love waiting on hold. An emotion-aware system using multimodal tokens would have something like [sarcasm] or an emotion embedding alongside the text. The LLM could interpret this as an unhappy user despite the positive words, and respond apologetically: “I’m really sorry for the long wait. That must be frustrating. Let me help speed things up.” The TTS, informed by the LLM’s intent to be apologetic, would speak in a concerned, sympathetic voice. All of this requires the pieces to share more than plain text – they need to share intent and tone information.
End-to-end speech systems: Another angle of evolution is collapsing the pipeline into a more end-to-end model. Meta AI, for instance, announced SeamlessM4T, a single model that can do speech-to-text, speech-to-speech, and text-to-speech translations across many languages ai.meta.com. While focused on translation, it exemplifies the trend: one model handling multiple modalities and tasks that traditionally were done by separate orchestrated components. In a SeamlessM4T scenario, input speech in Language A goes in, and output speech in Language B comes out, with the model internally learning the intermediate representation (it may implicitly do something like transcription, but it doesn’t output it – it goes straight to generating speech in the new language). The significance for voice assistants is that we could similarly train models that go speech in → speech out, without ever producing an intermediary text that a human would read. The “thinking” happens in between, but it might be in the form of abstract tokens or embeddings rather than human-readable text.
When we eliminate explicit text intermediaries, we open the door to preserving things like voice characteristics. For example, imagine a personal AI voice clone that listens to you and responds in a voice that sounds similar to your own (or some configured persona), and mirrors your emotional state appropriately. To do that, the system might carry over your vocal style from input to output or intentionally modulate it. Early experiments in this vein include models that can convert emotion in speech: given a monotone TTS output, modulate it to sound excited or sad as needed. If the orchestration doesn’t force everything through text, such direct audio-to-audio style transfer becomes easier.
Multimodal LLMs in the loop: The latest generation of AI models, like GPT-4, already began embracing multimodality (GPT-4 accepts image inputs, for instance). It’s not hard to imagine a near-future GPT-5 or similar model that can directly accept audio input tokens. In fact, OpenAI’s GPT-4 has an experimental variant (GPT-4V, Vision) that can describe images; an analogous “GPT-4A” (Audio) could take audio waveforms or audio tokens. The closed-source GPT-4 reportedly has “demonstrated potential of any-to-any LLMs for complex tasks, enabling omnidirectional input and output across images, speech, and text” arxiv.org. In other words, the idea of one model to rule them all – see, hear, and speak – is on the horizon. OpenAI already combined Whisper and GPT-4 (text) and a new TTS to power the voice chat feature in the ChatGPT app released in late 2023, but that was essentially the traditional pipeline packaged nicely. The next step would be more integration: e.g., a single API that you give an audio file and it directly responds with audio, internally handling the orchestration with possibly a unified model.
Research like MIO (Multimodal IO) goes one step further: it trained a foundation model on four modalities (speech, text, images, video) using discrete tokens for each, so it can understand/generate any combination arxiv.org, arxiv.org. These models treat, say, a snippet of speech as just another sequence of symbols akin to text. The boundary between ASR and LLM disappears – it’s all one transformer network doing it all. While MIO is a research prototype, it points to how future voice AIs might work under the hood.
All this doesn’t mean the orchestration layer disappears – rather, it changes form. Instead of a simple pipeline controller, the orchestration layer becomes more of a multimodal integration layer. It could be largely internal to a single model (if one model handles everything), or it might orchestrate between a few specialized models (e.g., one model converts raw audio to semantic tokens, another giant LLM processes those and emits response tokens, another model turns those tokens to speech). But critically, the interfaces between these parts carry richer information than before. They might carry emotion tokens, speaker identity embeddings, context tags, etc. The orchestrator’s job becomes managing these flows and perhaps making high-level decisions like: should I respond verbally or would a picture be better (if the device has a display)? Should I speak now or wait for the user to finish? These are higher-level orchestration decisions beyond just piping data along.
In summary, the evolution underway is making the orchestration layer multimodal and context-aware by design. The AI is starting to understand the music, not just the lyrics. When the user’s voice rises in anger or quivers in sadness, the next-gen assistant will “hear” that in the tokens it processes, reason about it (maybe deciding to change the conversation tact), and respond with speech that carries the appropriate tone. This is a transformative shift from the rigid old pipeline. It brings us to envisioning the future: what does the orchestration layer look like when all these advancements mature?
The Future: Token-Based Emotional Reasoning and the Multimodal Voice AI of Tomorrow
Standing at the frontier of voice AI, we can imagine an orchestration layer that is almost invisible – because the interaction with AI feels truly natural. In this future, talking to an AI might be indistinguishable from talking to a empathetic, super-knowledgeable friend. Let’s paint a picture of how the orchestration layer will enable that future:
Removing the Textual Barrier
In the future, voice AI might no longer convert everything to plain text as an intermediate. Instead, when you speak, your voice could be converted into a set of tokens that encapsulate your words and the way you said them. The system might use a universal language of thought that transcends human-readable text. For example, your sentence “I can’t believe it’s already Monday” might become something like: [Speaker=John][Tone=tired][Content=I cannot believe it is already Monday] as internal tokens (this is a simplified illustration – actual tokens would be numeric vectors learned by the model). The token-based emotional reasoning means the AI doesn’t drop the [Tone=tired] part; it actually uses it in reasoning. The large language model of the future would have been trained on data where tone mattered, so it knows that a “tired” tone might imply the speaker is not looking forward to Monday, maybe needs a gentle response or a joke to cheer them up. The AI’s response might similarly be composed with a tone: e.g. it might internally generate [Tone=empathetic][Content=I know the feeling. How about some coffee to kickstart the week?]. The orchestration layer (or the unified model) then ensures the TTS voices that reply with an empathetic intonation – perhaps a softer, comforting voice. This eliminates the blind spot that traditional systems had when converting speech to text: no information is unnecessarily thrown away.
Multimodal and Contextual Awareness
The orchestration layer of tomorrow will likely handle multiple input streams. Consider a scenario: you’re wearing AR glasses with a built-in AI assistant. It can see your surroundings (camera input), hear your voice (microphone), maybe even monitor your vital signs (wearable sensors). All these are modalities that provide context. The multimodal LLM at the core could take in a composite prompt: not just what you said, but what you’re looking at and your facial expression. If you say, “What do you think of this?” and you’re looking at a painting with a quizzical smile, the AI could combine the visual context (the painting image) and auditory context (your amused tone) to infer you might be asking for a fun commentary, not a factual description. It might then orchestrate a response that’s witty and spoken in a playful tone.
This means the orchestration layer might involve multi-sensor fusion, bringing together voice, vision, and other inputs before or within the LLM stage. In effect, the voice AI becomes an all-senses AI. Projects like MIO and AnyGPT already hint at AIs that can handle speech, images, and text together medium.com. Future assistants might also detect who is speaking (speaker recognition) as part of input tokens, allowing personalization – it will know it’s you, and perhaps recall your preferences or mood history.
A Single, Unified Model – Or Seemingly So
We may see a convergence where the distinction between STT, LLM, and TTS modules disappears behind a unified interface. From the user or developer perspective, you’ll just have a conversational AI model that you feed audio to and that gives you audio back. Internally it might still use separate components (for efficiency or specialization), but the orchestration is deeply integrated. OpenAI’s future offerings, Google’s Assistant updates, or new startups may provide end-to-end voice AI APIs. This would be analogous to how GPT-4 currently can do many text tasks that used to require separate models – one model now does question answering, summarizing, translating, coding help, etc., because it’s general enough. Similarly, a sufficiently powerful multimodal model could handle the whole voice conversation loop.
When the orchestration is handled by a single model, latency might decrease (less overhead passing data around), and weird errors might reduce (because the model can, for instance, decide to correct a misheard word on the fly using context, something hard to do in the old pipeline). It could also lead to more creative responses. For example, maybe the AI decides to respond not just with voice but also shows an image on your smart screen because it “thought” that would help (truly multimodal output). Already, AnyGPT demonstrated the ability to respond to a query in one modality with output in another (text in, speech out; image in, music out, etc.) medium.com. Voice AI will tap into that flexibility, orchestrating different modes for the best interaction.
Emotional Intelligence and Personalization
Perhaps the most exciting aspect for making voice AI engaging is emotional intelligence. We can expect the future orchestration layer to make emotion a first-class citizen. The assistant will not only recognize the user’s emotional state but also have a configurable or adaptive emotional style for itself. Just as humans modulate how we speak to match the situation (you speak gently to someone upset, or you adopt a cheerful tone when congratulating someone), AI will do the same. And it will be consistent over time – if you prefer a more formal, calm assistant voice versus a bubbly friendly one, the system could maintain that personality (this is like an “AI persona” setting, which some current assistants have in a limited way). Large models are already known to exhibit “styles” or “personas” in how they respond (ChatGPT can role-play or take on a tone if instructed). Future voice AI likely will explicitly orchestrate the persona layer.
We might even see dynamic emotional adaptation: the AI starts an interaction in a default polite tone, but if it senses you are getting frustrated, the orchestration layer switches the AI’s approach – perhaps becoming more apologetic, simplifying its language, or even injecting a bit of empathy like “I’m sorry, this is taking a while, let’s try this...”. The end-to-end model might have been trained on dialogues labeled with emotion tags so it knows how to handle such shifts. As an example, one could train a model on customer service conversations where the AI’s goal is not only to solve the issue but to keep the customer happy, learning how to de-escalate tension. The result in a personal assistant context is an AI that feels attentive and caring.
The Role of the Orchestration Layer in 2030
By 2030, we might not talk about an “orchestration layer” as a separate piece of software like we do today. It will be more of an architectural concept that’s largely baked into AI models and platforms. It will ensure that all the pieces – voice input, comprehension, external knowledge sources, voice output – work together in a split-second to serve the user’s needs. It might leverage specialized subsystems (for instance, a future assistant might still use a separate module for factual knowledge or real-time data, orchestrated by the LLM which decides when to call it). In that sense, orchestration could involve tool use: the LLM might orchestrate calling an API (like “check calendar” or “turn on the lights”) in the middle of a conversation and then continue the dialogue. We already see glimpses of this with systems like HuggingGPT (where an LLM coordinates other AI models) teneo.ai. For a home assistant, the orchestrator might manage not just the voice conversation, but the whole ecosystem of IoT devices and web services in response to voice commands.
The multimodal LLM effectively becomes the new orchestration layer, as it can internally decide how to route requests or whether to output text, speech, or action. One can think of it as the assistant’s “brain” has grown to absorb the orchestrator role. It’s similar to how in the early days of computing you had separate processors for different tasks, and over time they might get integrated into one chip or tightly coordinated units.
Inspiring the Future from Here in Hastings
This journey from the clunky voice gadgets of the 1960s to the emotionally intelligent AIs of tomorrow is not just a Silicon Valley story – it’s a human story, and one that communities like Hastings, Minnesota can actively participate in. We live in a time when a developer in a small town can access powerful AI models via the cloud and contribute ideas on par with the largest labs. The evolving orchestration layer is essentially about making technology more in tune with people, and who understands people better than a close-knit community?
Hastings has a tradition of innovation and a strong educational backbone. By understanding where voice AI is headed, local talent can ride the wave of innovation. Perhaps it will be a team at a Minnesota startup that cracks the code on a particularly tricky aspect of emotional AI, or a student at a local college who designs a new way to visualize multimodal tokens, or a civic hackathon that employs voice AI to improve city services for residents (imagine a local information hotline that truly “gets” the caller’s urgency or confusion and responds with empathy). The visionary path we outlined – making AI more human-like in communication – requires diverse minds. It’s not just about cutting-edge algorithms, but also about empathy, creativity, and understanding human nature. Those qualities are abundant in communities like ours.
By positioning Hastings as a hub for forward-thinking tech, even in a niche like voice orchestration, we can attract companies and research projects. It could open opportunities for local workshops on AI, robotics teams in schools integrating voice interfaces, or partnerships with universities. The epic story of the orchestration layer, from Audrey to Alexa to whatever comes next, can inspire the next generation of engineers and designers here to ask: What role can I play in this saga? Maybe one of you reading this will help develop the token system that finally enables AIs to truly grasp irony or maybe design the user experience for a multimodal assistant in healthcare that comforts patients with a warm bedside manner. The possibilities are as open as a microphone listening for a wake word.
In conclusion, the orchestration layer in voice AI has evolved from a simple pipeline integrator into a sophisticated, and soon, possibly holistic, symphony conductor for multi-sense, emotionally attuned AI interactions. It originated to solve a practical problem – linking speech in to speech out – but it’s becoming the key to unlocking genuinely natural conversations with machines. The journey is ongoing, but each breakthrough brings us closer to an era where AI not only hears our words but also understands our hearts. That is a future to get excited about. Here in Hastings, let’s tune our skills and imagination to this melody of innovation. After all, the next big voice in AI could be yours.